

Enhancing cross view geo localization through global local quadrant interaction network
- PMID: 41023367
- PMCID: PMC12480966
- DOI: 10.1038/s41598-025-18935-6
Enhancing cross view geo localization through global local quadrant interaction network
Abstract
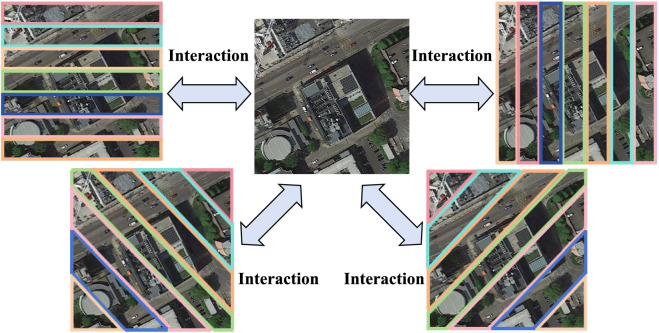
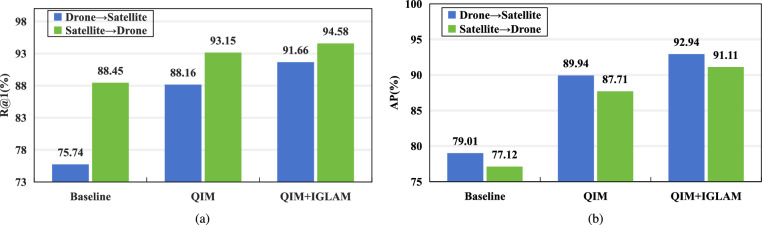
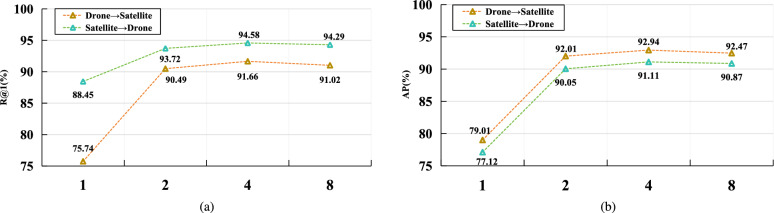
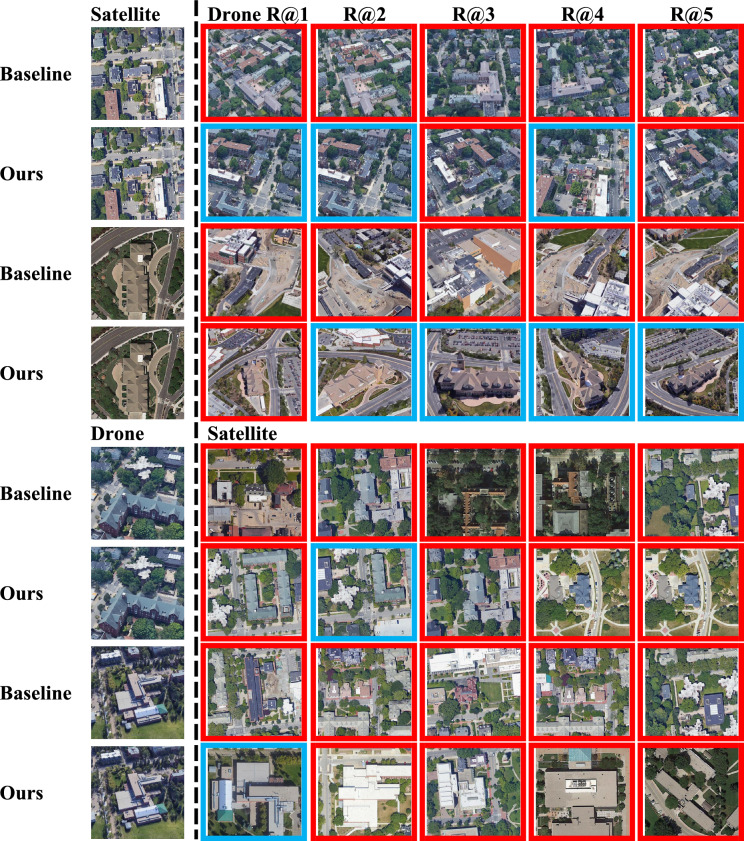
Cross-view geo-localization aims to match images of the same location captured from different perspectives, such as drone and satellite views. This task is inherently challenging due to significant visual discrepancies caused by viewpoint variations. Existing approaches often rely on global descriptors or limited directional cues, failing to effectively integrate diverse spatial information and global-local interactions. To address these limitations, we propose the Global-Local Quadrant Interaction Network (GLQINet), which enhances feature representation through two key components: the Quadrant Insight Module (QIM) and the Integrated Global-Local Attention Module (IGLAM). QIM partitions feature maps into directional quadrants, refining multi-scale spatial representations while preserving intra-class consistency. Meanwhile, IGLAM bridges global and local features by aggregating high-association feature stripes, reinforcing semantic coherence and spatial correlations. Extensive experiments on the University-1652 and SUES-200 benchmarks demonstrate that GLQINet significantly improves geo-localization accuracy, achieving state-of-the-art performance and effectively mitigating cross-view discrepancies.
Keywords: Cross-view; Geo-localization; Integrated global-local attention; Quadrant insight.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures



References
Grants and funding
LinkOut - more resources
Full Text Sources
