

Assessment of the validity of ChatGPT-3.5 responses to patient-generated queries following BPH surgery
- PMID: 41028089
- PMCID: PMC12484858
- DOI: 10.1038/s41598-025-13077-1
Assessment of the validity of ChatGPT-3.5 responses to patient-generated queries following BPH surgery
Abstract
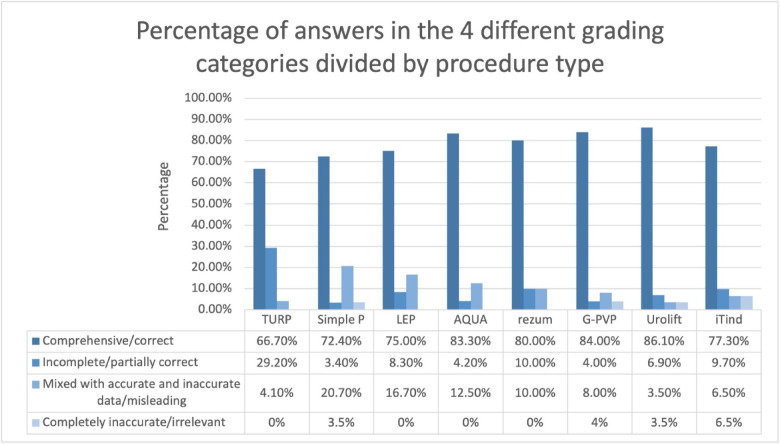
The rapid advancement of artificial intelligence, particularly large language models like ChatGPT-3.5, presents promising applications in healthcare. This study evaluates ChatGPT-3.5's validity in responding to post-operative patient inquiries following surgery for benign prostatic hyperplasia (BPH). Common patient-generated questions were sourced from discharge instructions, online forums, and social media, covering various BPH surgical modalities. ChatGPT-3.5 responses were assessed by two senior urology residents using pre-defined criteria, with discrepancies resolved by a third reviewer. A total of 496 responses were reviewed, with 280 excluded. Among the 216 graded responses, 78.2% were comprehensive and correct, 9.3% were incomplete or partially correct, 10.2% contained a mix of accurate and inaccurate information, and 2.3% were entirely incorrect. Newer procedures (Aquablation, Rezum, iTIND) had a higher percentage of correct answers compared to traditional techniques (TURP, simple prostatectomy). The most common errors involved missing context or incorrect details (36.6%). These findings suggest that ChatGPT-3.5 has potential in providing accurate post-operative guidance for BPH patients. However, concerns regarding incomplete and misleading responses highlight the need for further refinement to improve AI-generated medical advice and ensure patient safety. Future research should focus on enhancing AI reliability in clinical applications.
Keywords: Artificial intelligence; Minimally invasive surgical procedures; Natural language processing; Postoperative care; Prostatic hyperplasia.
© 2025. The Author(s).
Conflict of interest statement
Declarations. Competing interests: The authors declare no competing interests.
Figures


References
-
- Radford, A., Narasimhan, K., Salimans, T. & Sutskever, I. Improving language understanding by generative pre-training. (2018).
-
- Lee, H. The rise of chatgpt: exploring its potential in medical education. Anat. Sci. Educ.17 (5), 926–931 (2024). - PubMed
-
- Zhang, A. et al. ChatGPT for improving postoperative instructions in multiple fields of plastic surgery. J. Plast. Reconstr. Aesthet. Surg.99, 201–208 (2024). - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
