

Can Multimodal Large Language Models Diagnose Diabetic Retinopathy from Fundus Photos? A Quantitative Evaluation
- PMID: 41030829
- PMCID: PMC12478077
- DOI: 10.1016/j.xops.2025.100911
Can Multimodal Large Language Models Diagnose Diabetic Retinopathy from Fundus Photos? A Quantitative Evaluation
Abstract
Objective: To evaluate the diagnostic accuracy of 4 multimodal large language models (MLLMs) in detecting and grading diabetic retinopathy (DR) using their new image analysis features.
Design: A single-center retrospective study.
Subjects: Patients diagnosed with prediabetes and diabetes.
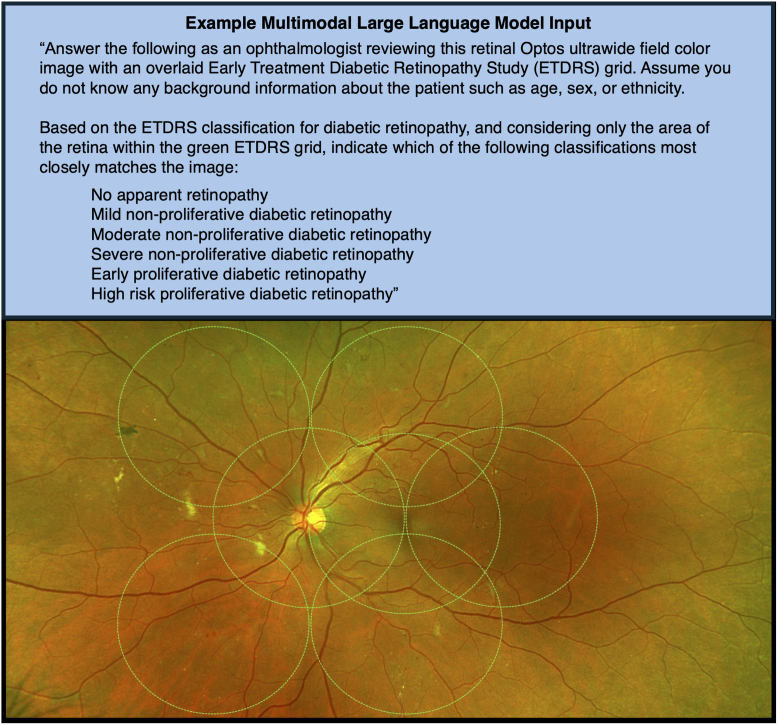
Methods: Ultra-widefield fundus images from patients seen at the University of California, San Diego, were graded for DR severity by 3 retina specialists using the ETDRS classification system to establish ground truth. Four MLLMs (ChatGPT-4o, Claude 3.5 Sonnet, Google Gemini 1.5 Pro, and Perplexity Llama 3.1 Sonar/Default) were tested using 4 distinct prompts. These assessed multiple-choice disease diagnosis, binary disease classification, and disease severity. Multimodal large language models were assessed for accuracy, sensitivity, and specificity in identifying the presence or absence of DR and relative disease severity.
Main outcome measures: Accuracy, sensitivity, and specificity of diagnosis.
Results: A total of 309 eyes from 188 patients were included in the study. The average patient age was 58.7 (56.7-60.7) years, with 55.3% being female. After specialist grading, 70.2% of eyes had DR of varying severity, and 29.8% had no DR. For disease identification with multiple choices provided, Claude and ChatGPT scored significantly higher (P < 0.0006, per Bonferroni correction) than other MLLMs for accuracy (0.608-0.566) and sensitivity (0.618-0.641). In binary DR versus no DR classification, accuracy was the highest for ChatGPT (0.644) and Perplexity (0.602). Sensitivity varied (ChatGPT [0.539], Perplexity [0.488], Claude [0.179], and Gemini [0.042]), whereas specificity for all models was relatively high (range: 0.870-0.989). For the DR severity prompt with the best overall results (Prompt 3.1), no significant differences between models were found in accuracy (Perplexity [0.411], ChatGPT [0.395], Gemini [0.392], and Claude [0.314]). All models demonstrated low sensitivity (Perplexity [0.247], ChatGPT [0.229], Gemini [0.224], and Claude [0.184]). Specificity ranged from 0.840 to 0.866.
Conclusions: Multimodal large language models are powerful tools that may eventually assist retinal image analysis. Currently, however, there is variability in the accuracy of image analysis, and diagnostic performance falls short of clinical standards for safe implementation in DR diagnosis and grading. Further training and optimization of common errors may enhance their clinical utility.
Financial disclosures: Proprietary or commercial disclosure may be found in the Footnotes and Disclosures at the end of this article.
Keywords: Artificial intelligence; Diabetic retinopathy; Image analysis; Multimodal large language model; Ultra-widefield fundus photography.
© 2025 by the American Academy of Ophthalmologyé.
Figures
References
-
- Wong T.Y., Sun J., Kawasaki R., et al. Guidelines on diabetic eye care: the international council of ophthalmology recommendations for screening, follow-up, referral, and treatment based on resource settings. Ophthalmology. 2018;125:1608–1622. - PubMed
-
- Nørgaard M.F., Grauslund J. Automated screening for diabetic retinopathy – a systematic review. Ophthalmic Res. 2018;60:9–17. - PubMed
LinkOut - more resources
Full Text Sources
