

Evaluation of reliability, repeatability, and confidence of ChatGPT for screening, monitoring, and treatment of interstitial lung disease in patients with systemic autoimmune rheumatic diseases
- PMID: 41036434
- PMCID: PMC12480815
- DOI: 10.1177/20552076251384233
Evaluation of reliability, repeatability, and confidence of ChatGPT for screening, monitoring, and treatment of interstitial lung disease in patients with systemic autoimmune rheumatic diseases
Abstract
Background: In recent years, potential applications of ChatGPT in medication-related practices have drawn great attention for its intuitive user interfaces, chatbot, and powerful analytical capabilities. However, whether ChatGPT can be broadly applied in clinical practice remains controversial. Early screening, monitoring, and timely treatment are crucial for improving outcomes of interstitial lung disease (ILD) in systemic autoimmune rheumatic diseases (SARDs) due to its high morbidity and mortality rate. This study aimed to evaluate the reliability, repeatability, and confidence of ChatGPT models (GPT-4, GPT-4o mini, and GPT-4o) in delivering guideline-based recommendations for the screening, monitoring, and treatment of ILD in SARD patients.
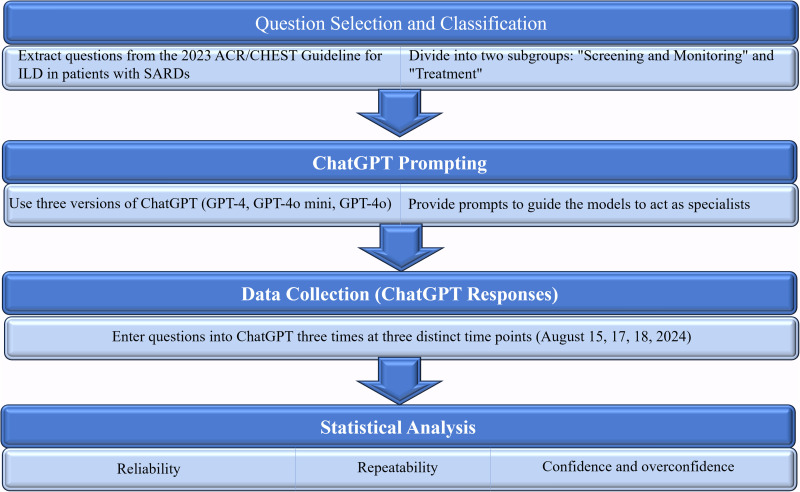
Methods: Questions derived from the ACR/CHEST guideline for ILD patients with SARDs were used to benchmark three versions of ChatGPT (GPT-4, GPT-4o mini, and GPT-4o) across three separate attempts. The responses were recorded, and the reliability, repeatability, and confidence were analyzed with the recommendations from the guideline.
Results: GPT-4 demonstrated significant variability in reliability across the three attempts (P = .007). In contrast, the other versions showed no significant differences. GPT-4 and GPT-4o mini exhibited substantial interrater agreement (Kendall's W = 0.747 and 0.765, respectively), whereas GPT-4o demonstrated almost perfect interrater agreement (Kendall's W = 0.816). All three versions showed statistically significant differences in high confidence ratings (confidence score of ≥ 8 on the 1-10 scale) across the three attempts (P < .01). Given the higher consistency of GPT-4o and GPT-4o mini, a further comparison was conducted between them on the third attempt. No significant difference was observed in accuracy percentages across the third attempt between GPT-4o and GPT-4o mini (P = .597). Similarly, interrater agreement across the three attempts was not significantly different for both GPT-4o and GPT-4o mini (P = .152). Furthermore, the overconfidence percentage (confidence score of ≥8 assigned to incorrect answers) was 100% (22 of 22) for GPT-4o and 22.7% (10 of 44) for GPT-4o mini, respectively (P < .01).
Conclusions: GPT-4o mini and GPT-4o demonstrated stable reliability across all three attempts, whereas GPT-4 did not. The repeatability of GPT-4o tended to perform better than GPT-4o mini, although this difference was not statistically significant. Additionally, GPT-4o exhibited a higher tendency toward overconfidence compared to GPT-4o mini. Overall, the GPT-4o models performed most effectively in managing SARD-ILD but may exhibit overconfidence in certain scenarios.
Keywords: ChatGPT; Systemic autoimmune rheumatic diseases; interstitial lung disease.
© The Author(s) 2025.
Conflict of interest statement
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Figures



References
-
- Mintz Y, Brodie R. Introduction to artificial intelligence in medicine. Minim Invasiv Ther 2019; 28: 73–81. - PubMed
LinkOut - more resources
Full Text Sources
