

Attention to quantum complexity
- PMID: 41071874
- PMCID: PMC12513418
- DOI: 10.1126/sciadv.adu0059
Attention to quantum complexity
Abstract
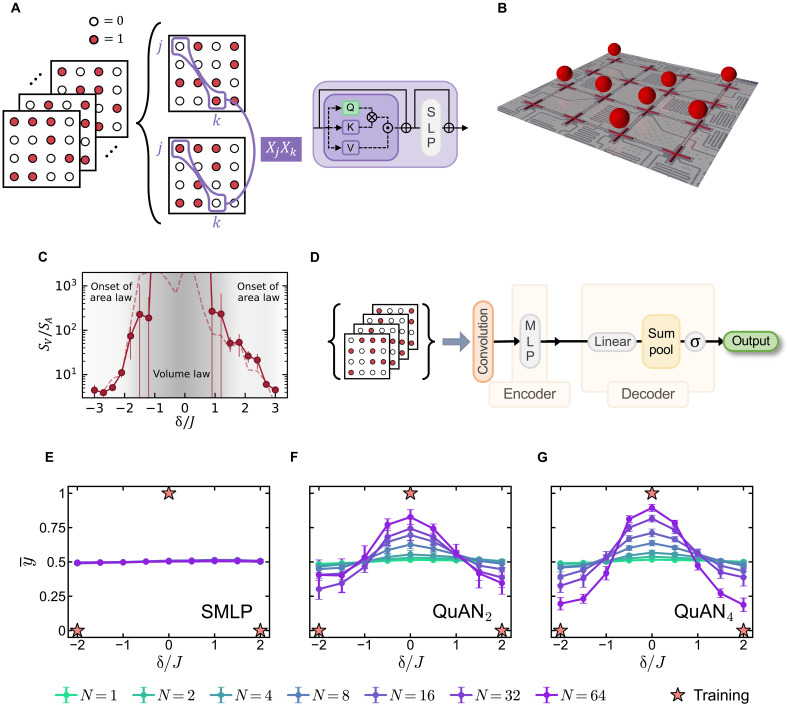
The imminent era of error-corrected quantum computing demands robust methods to characterize quantum state complexity from limited, noisy measurements. We introduce the Quantum Attention Network (QuAN), a classical artificial intelligence (AI) framework leveraging attention mechanisms tailored for learning quantum complexity. Inspired by large language models, QuAN treats measurement snapshots as tokens while respecting permutation invariance. Combined with our parameter-efficient miniset self-attention block, this enables QuAN to access high-order moments of bit-string distributions and preferentially attend to less noisy snapshots. We test QuAN across three quantum simulation settings: driven hard-core Bose-Hubbard model, random quantum circuits, and toric code under coherent and incoherent noise. QuAN directly learns entanglement and state complexity growth from experimental computational basis measurements, including complexity growth in random circuits from noisy data. In regimes inaccessible to existing theory, QuAN unveils the complete phase diagram for noisy toric code data as a function of both noise types, highlighting AI's transformative potential for assisting quantum hardware.
Figures



References
-
- Bluvstein D., Evered S. J., Geim A. A., Li S. H., Zhou H., Manovitz T., Ebadi S., Cain M., Kalinowski M., Hangleiter D., Bonilla Ataides J. P., Maskara N., Cong I., Gao X., Sales Rodriguez P., Karolyshyn T., Semeghini G., Gullans M. J., Greiner M., Vuletić V., Lukin M. D., Logical quantum processor based on reconfigurable atom arrays. Nature 626, 58–65 (2024). - PMC - PubMed
-
- A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, “Attention is all you need,” in Proceedings of the 31st International Conference on Neural Information Processing Systems (Curran Associates Inc., 2017), p. 6000–6010; https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547de....
-
- A. Parikh, O. Täckström, D. Das, J. Uszkoreit, A decomposable attention model for natural language inference. arXiv:1606.01933 (2016).
LinkOut - more resources
Full Text Sources
