

Consistent performance of large language models in rare disease diagnosis across ten languages and 4917 cases
- PMID: 41092581
- PMCID: PMC12552141
- DOI: 10.1016/j.ebiom.2025.105957
Consistent performance of large language models in rare disease diagnosis across ten languages and 4917 cases
Abstract
Background: Large language models (LLMs) are increasingly used medicine for diverse applications including differential diagnostic support. The training data used to create LLMs such as the Generative Pretrained Transformer (GPT) predominantly consist of English-language texts, but LLMs could be used across the globe to support diagnostics if language barriers could be overcome. Initial pilot studies on the utility of LLMs for differential diagnosis in languages other than English have shown promise, but a large-scale assessment on the relative performance of these models in a variety of European and non-European languages on a comprehensive corpus of challenging rare-disease cases is lacking.
Methods: We created 4917 clinical vignettes using structured data captured with Human Phenotype Ontology (HPO) terms with the Global Alliance for Genomics and Health (GA4GH) Phenopacket Schema. These clinical vignettes span a total of 360 distinct genetic diseases with 2525 associated phenotypic features. We used translations of the Human Phenotype Ontology together with language-specific templates to generate prompts in English, Chinese, Czech, Dutch, French, German, Italian, Japanese, Spanish, and Turkish. We applied GPT-4o, version gpt-4o-2024-08-06, and the medically fine-tuned Meditron3-70B to the task of delivering a ranked differential diagnosis using a zero-shot prompt. An ontology-based approach with the Mondo disease ontology was used to map synonyms and to map disease subtypes to clinical diagnoses in order to automate evaluation of LLM responses.
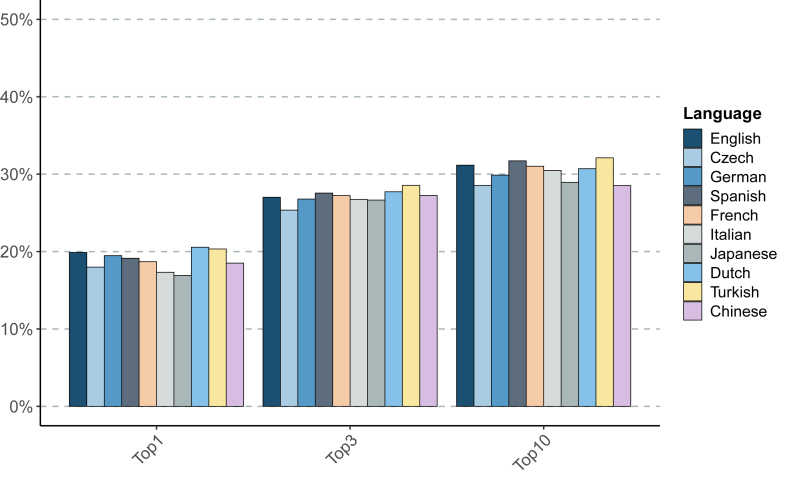
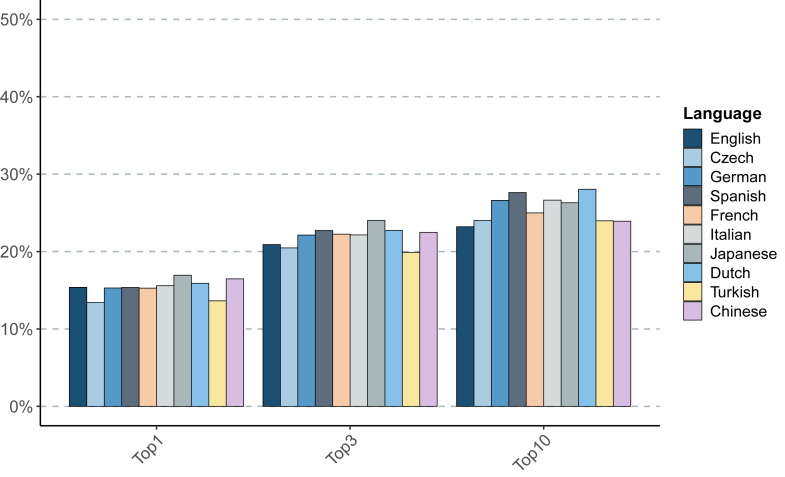
Findings: For English, GPT-4o placed the correct diagnosis at the first rank 19.9% and within the top-3 ranks 27.0% of the time. In comparison, for the nine non-English languages tested here the correct diagnosis was placed at rank 1 between 16.9% and 20.6%, within top-3 between 25.4% and 28.6% of cases. The Meditron3 model placed the correct diagnosis within the first 3 ranks for 20.9% of cases in English and between 19.9% and 24.0% for the other nine languages.
Interpretation: The differential diagnostic performance of LLMs across a comprehensive corpus of rare-disease cases was largely consistent across the ten languages tested. This suggests that the utility of LLMs in clinical settings may extend to non-English clinical settings.
Funding: NHGRI 5U24HG011449, 5RM1HG010860, R01HD103805 and R24OD011883. P.N.R. was supported by a Professorship of the Alexander von Humboldt Foundation; P.L. was supported by a National Grant (PMP21/00063 ONTOPREC-ISCIII, Fondos FEDER). C.M., J.R. and J.H.C. were supported in part by the Director, Office of Science, Office of Basic Energy Sciences, of the US Department of Energy (Contract No. DE-AC0205CH11231).
Keywords: Artificial intelligence; Genomic diagnostics; Global Alliance for Genomics and Health; Human phenotype ontology; Large language model; Phenopacket schema.
Copyright © 2025 The Author(s). Published by Elsevier B.V. All rights reserved.
Conflict of interest statement
Declaration of interests MH is a co-founder of Alamya Health. D.S. received a payment by Sanofi for a presentation in a continuing medical education course about AI and rare diseases.
Figures

Update of
-
Consistent Performance of GPT-4o in Rare Disease Diagnosis Across Nine Languages and 4967 Cases.medRxiv [Preprint]. 2025 Feb 28:2025.02.26.25322769. doi: 10.1101/2025.02.26.25322769. medRxiv. 2025. Update in: EBioMedicine. 2025 Nov;121:105957. doi: 10.1016/j.ebiom.2025.105957. PMID: 40061308 Free PMC article. Updated. Preprint.
References
-
- Statistics of common crawl monthly archives by commoncrawl. https://commoncrawl.github.io/cc-crawl-statistics/plots/languages
-
- Hayase J., Liu A., Choi Y., Oh S., Smith N.A. The Thirty-Eighth Annual Conference on Neural Information Processing Systems. 2024. Data mixture inference attack: BPE tokenizers reveal training data compositions.https://openreview.net/pdf?id=EHXyeImux0
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
