

Sequence mapping by electronic PCR
- PMID: 9149949
- PMCID: PMC310656
- DOI: 10.1101/gr.7.5.541
Sequence mapping by electronic PCR
Abstract
The highly specific and sensitive PCR provides the basis for sequence-tagged sites (STSs), unique landmarks that have been used widely in the construction of genetic and physical maps of the human genome. Electronic PCR (e-PCR) refers to the process of recovering these unique sites in DNA sequences by searching for subsequences that closely match the PCR primers and have the correct order, orientation, and spacing that they could plausibly prime the amplification of a PCR product of the correct molecular weight. A software tool was developed to provide an efficient implementation of this search strategy and allow the sort of en masse searching that is required for modern genome analysis. Some sample searches were performed to demonstrate a number of factors that can affect the likelihood of obtaining a match. Analysis of one large sequence database record revealed the presence of several microsatellite and gene-based markers and allowed the exact base-pair distances among them to be calculated. This example provides a demonstration of how e-PCR can be used to integrate the growing body of genomic sequence data with existing maps, reveal relationships among markers that existed previously on different maps, and correlate genetic distances with physical distances.
Figures
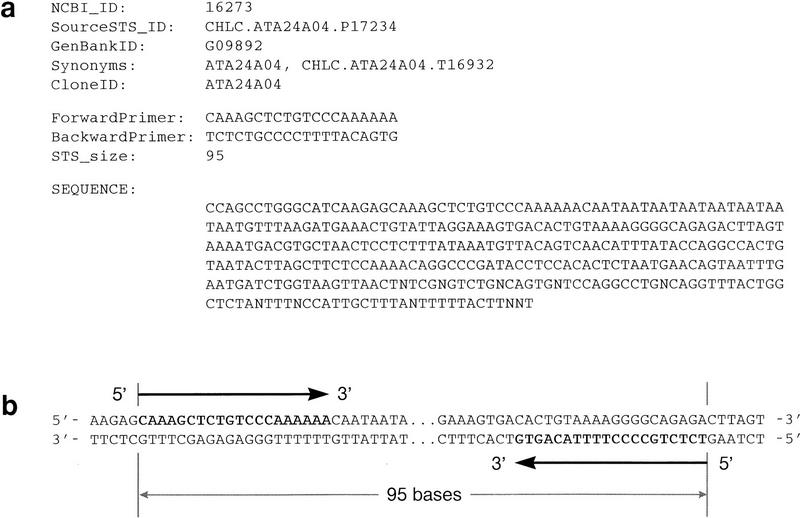
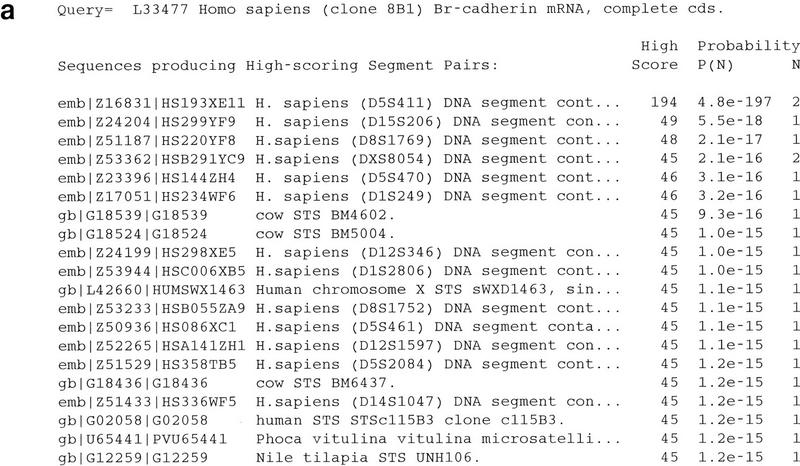

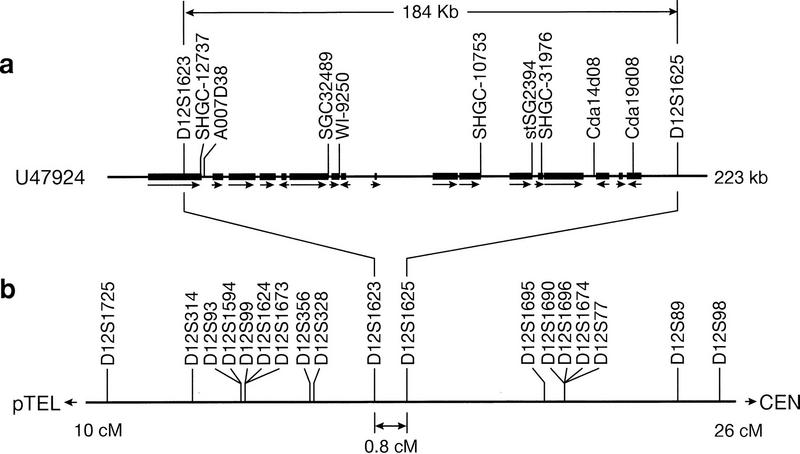
References
-
- Altschul SF, Gish W, Miller W, Myers EW, Lipman DJ. Basic local alignment search tool. J Mol Biol. 1990;215:403–410. - PubMed
-
- Altschul SF, Boguski MS, Gish W, Wootton JC. Issues in searching molecular sequence databases. Nature Genet. 1994;6:119–129. - PubMed
-
- Ansari-Lari MA, Muzny DM, Lu J, Lu F, Lilley CE, Spanos S, Malley T, Gibbs RA. A gene-rich cluster between the CD4 and triosephosphate isomerase genes at human chromosome 12p13. Genome Res. 1996;6:314–326. - PubMed
-
- Bangham CRM. The polymerase chain reaction: Getting started. In: Mathew CG, editor. Protocols in human molecular genetics. Clifton, NJ: Humana Press; 1991. pp. 1–8.
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
Miscellaneous