

A Z-DNA binding domain present in the human editing enzyme, double-stranded RNA adenosine deaminase
- PMID: 9237992
- PMCID: PMC22942
- DOI: 10.1073/pnas.94.16.8421
A Z-DNA binding domain present in the human editing enzyme, double-stranded RNA adenosine deaminase
Abstract
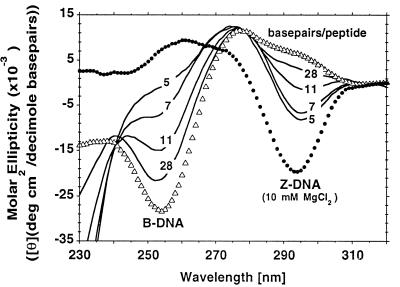
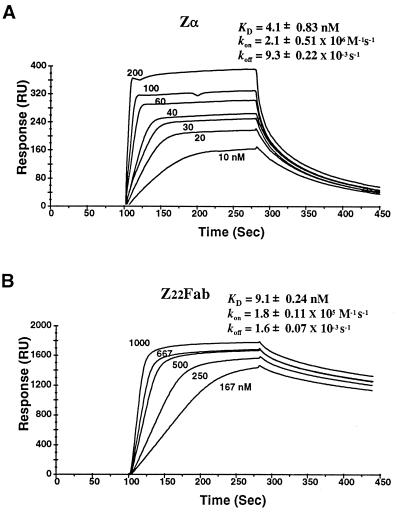
Editing of RNA changes the read-out of information from DNA by altering the nucleotide sequence of a transcript. One type of RNA editing found in all metazoans uses double-stranded RNA (dsRNA) as a substrate and results in the deamination of adenosine to give inosine, which is translated as guanosine. Editing thus allows variant proteins to be produced from a single pre-mRNA. A mechanism by which dsRNA substrates form is through pairing of intronic and exonic sequences before the removal of noncoding sequences by splicing. Here we report that the RNA editing enzyme, human dsRNA adenosine deaminase (DRADA1, or ADAR1) contains a domain (Zalpha) that binds specifically to the left-handed Z-DNA conformation with high affinity (KD = 4 nM). As formation of Z-DNA in vivo occurs 5' to, or behind, a moving RNA polymerase during transcription, recognition of Z-DNA by DRADA1 provides a plausible mechanism by which DRADA1 can be targeted to a nascent RNA so that editing occurs before splicing. Analysis of sequences related to Zalpha has allowed identification of motifs common to this class of nucleic acid binding domain.
Figures


References
-
- Bass B L. In: The RNA World. Gesteland R F, Atkins J F, editors. Plainview, NY: Cold Spring Harbor Lab. Press; 1993. pp. 383–418.
-
- Verdoorn T A, Burnashev N, Monyer H, Seeburg P H, Sakmann B. Science. 1991;252:1715–1718. - PubMed
-
- Hume R I, Dingledine R, Heinemann S F. Science. 1991;253:1028–1031. - PubMed
-
- Sommer B, Kohler M, Sprengel R, Seeburg P H. Cell. 1991;67:11–19. - PubMed
-
- Kohler M, Burnashev N, Sakmann B, Seeburg P H. Neuron. 1993;10:491–500. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
