

Temporal and spectral sensitivity of complex auditory neurons in the nucleus HVc of male zebra finches
- PMID: 9570809
- PMCID: PMC6793129
- DOI: 10.1523/JNEUROSCI.18-10-03786.1998
Temporal and spectral sensitivity of complex auditory neurons in the nucleus HVc of male zebra finches
Abstract
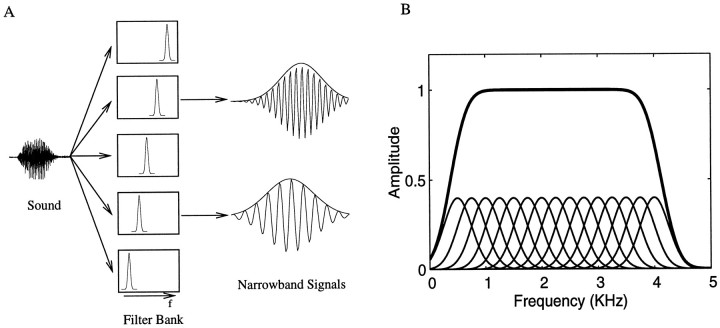
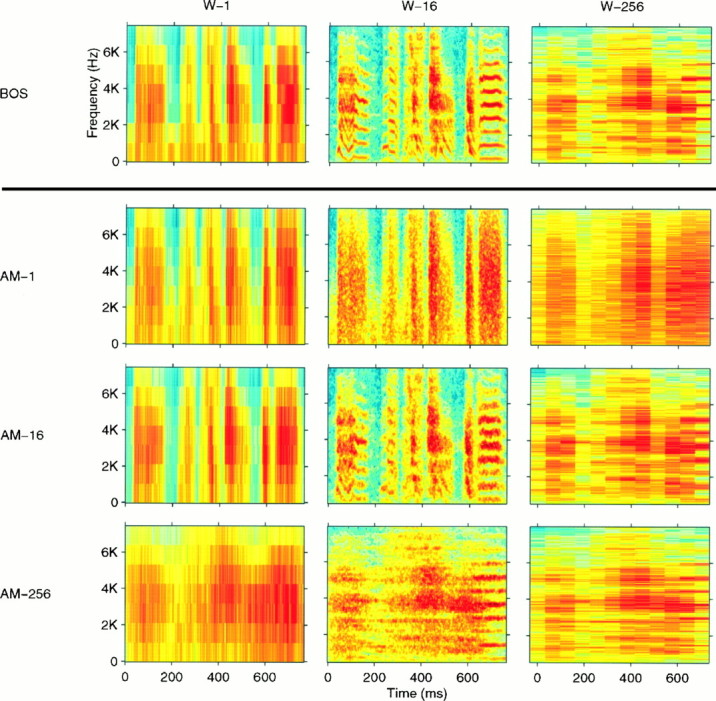
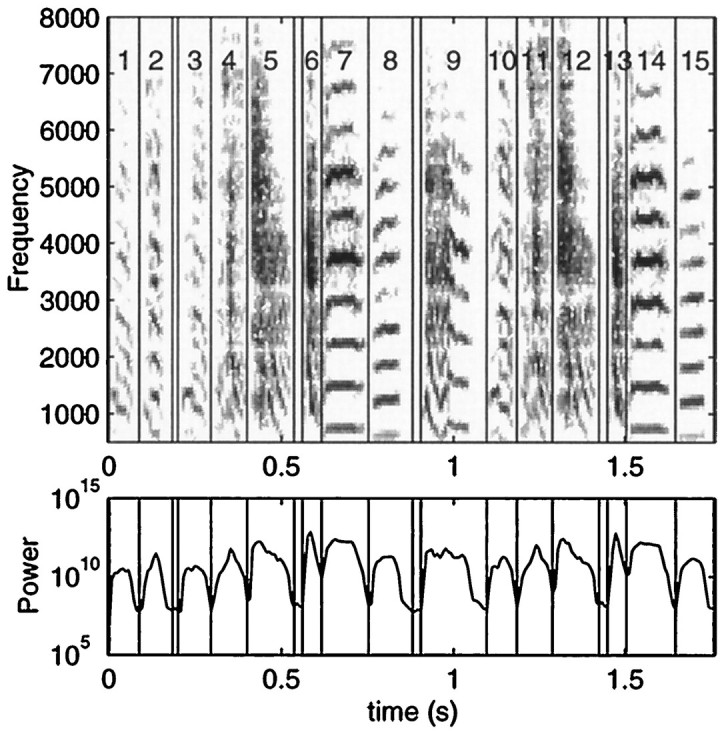
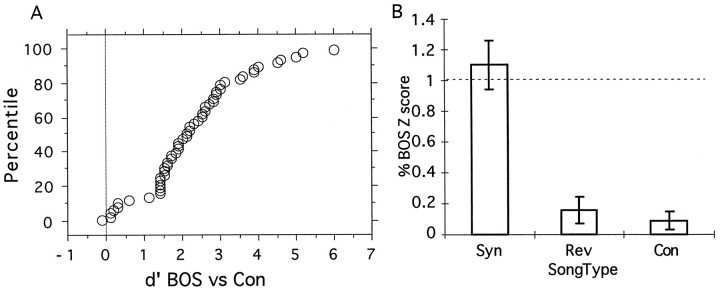
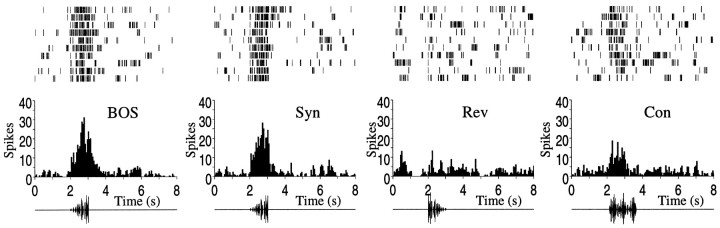
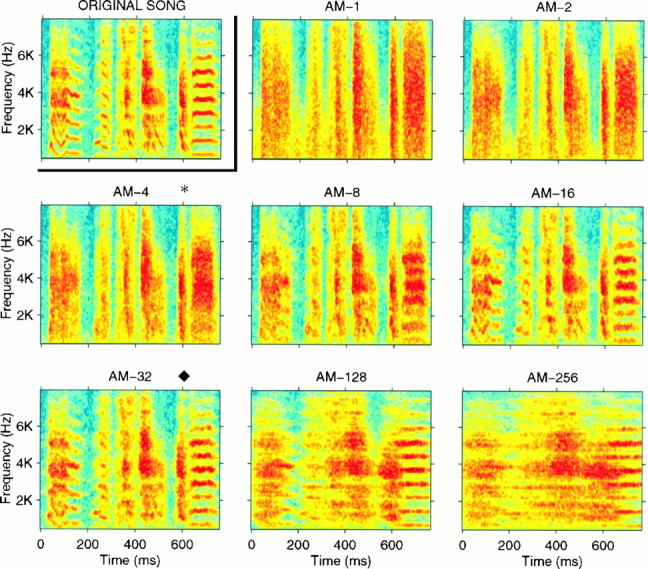
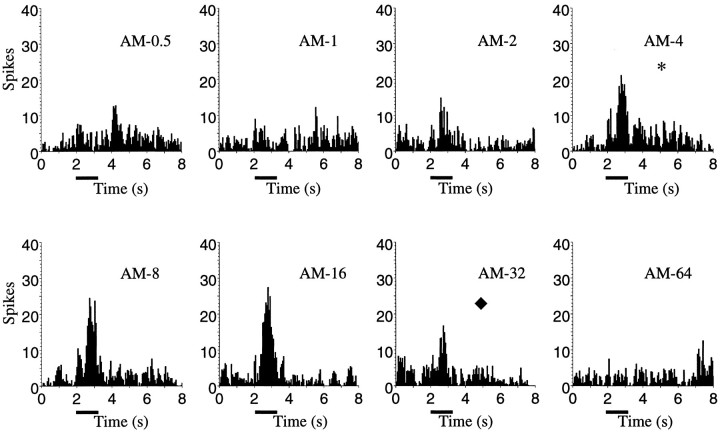
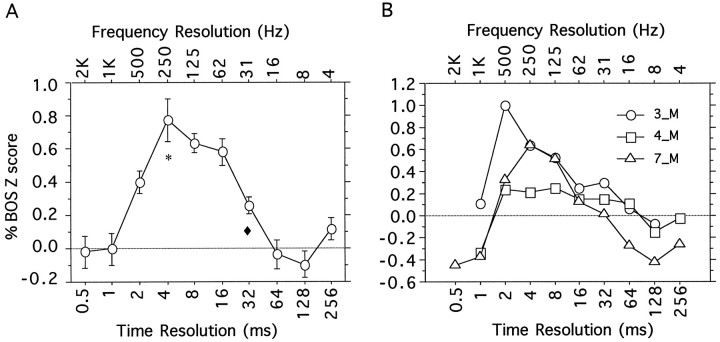
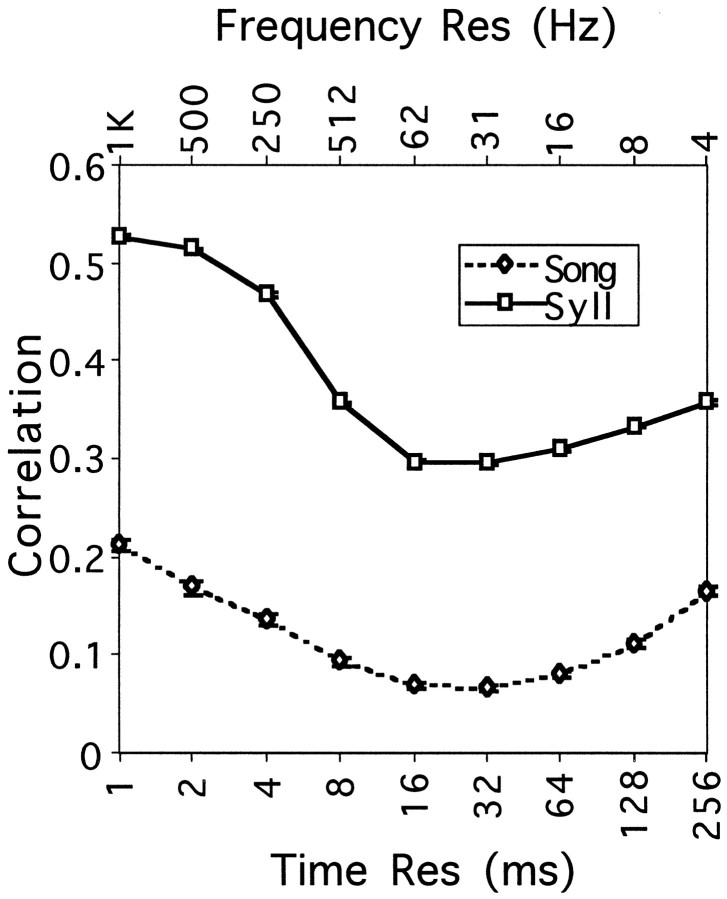
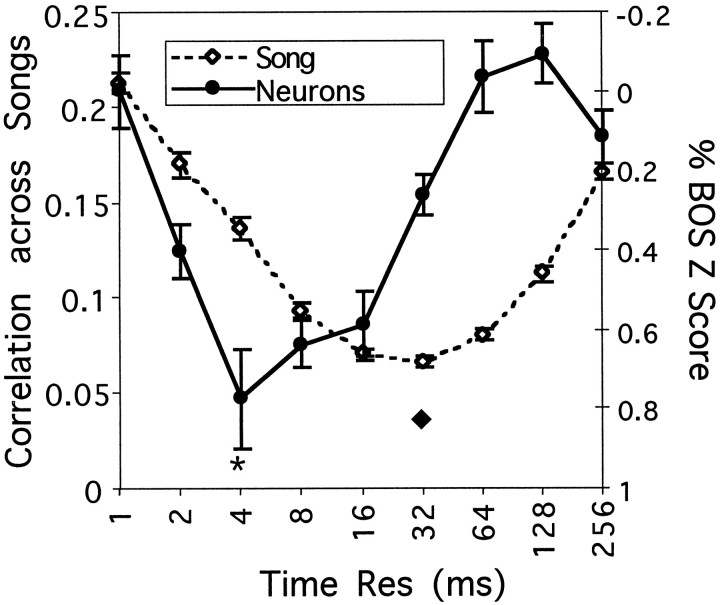
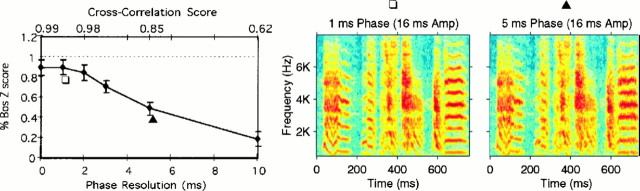
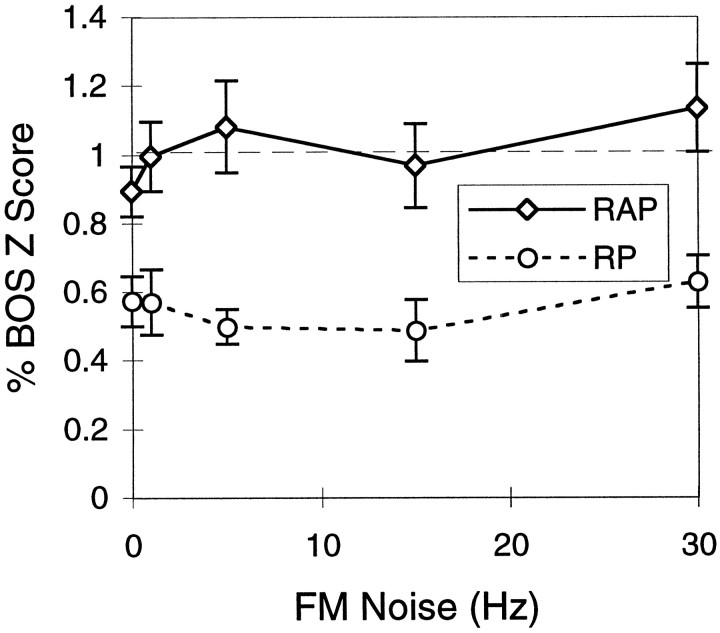
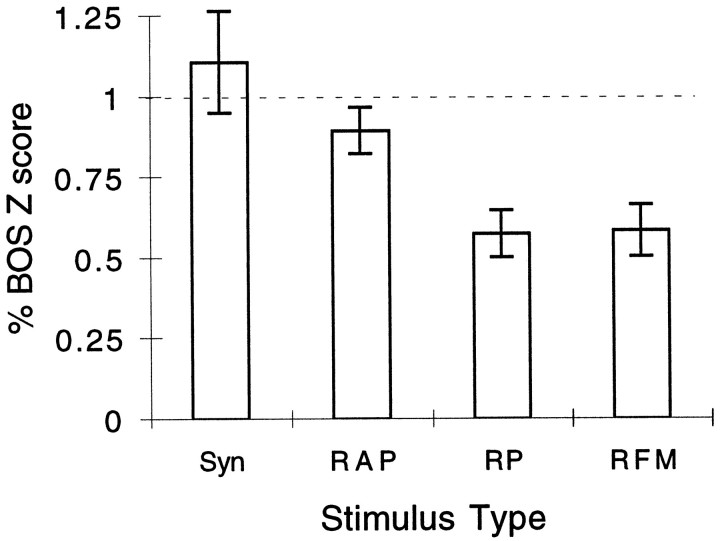
Complex vocalizations, such as human speech and birdsong, are characterized by their elaborate spectral and temporal structure. Because auditory neurons of the zebra finch forebrain nucleus HVc respond extremely selectively to a particular complex sound, the bird's own song (BOS), we analyzed the spectral and temporal requirements of these neurons by measuring their responses to systematically degraded versions of the BOS. These synthetic songs were based exclusively on the set of amplitude envelopes obtained from a decomposition of the original sound into frequency bands and preserved the acoustical structure present in the original song with varying degrees of spectral versus temporal resolution, which depended on the width of the frequency bands. Although both excessive temporal or spectral degradation eliminated responses, HVc neurons responded well to degraded synthetic songs with time-frequency resolutions of approximately 5 msec or 200 Hz. By comparing this neuronal time-frequency tuning with the time-frequency scales that best represented the acoustical structure in zebra finch song, we concluded that HVc neurons are more sensitive to temporal than to spectral cues. Furthermore, neuronal responses to synthetic songs were indistinguishable from those to the original BOS only when the amplitude envelopes of these songs were represented with 98% accuracy. That level of precision was equivalent to preserving the relative time-varying phase across frequency bands with resolutions finer than 2 msec. Spectral and temporal information are well known to be extracted by the peripheral auditory system, but this study demonstrates how precisely these cues must be preserved for the full response of high-level auditory neurons sensitive to learned vocalizations.
Figures
References
-
- Brugge JF, Merzenich MM. Responses of neurons in auditory cortex of the macaque monkey to monaural and binaural stimulation. J Neurophysiol. 1973;36:1138–1158. - PubMed
-
- Cohen L. Time-frequency analysis. Prentice Hall; Englewood Cliffs, NJ: 1995.
-
- Dear SP, Fritz J, Haresign T, Ferragamo M, Simmons JA. Tonotopic and functional organization in the auditory cortex of the big brown bat, Eptesicus fuscus. J Neurophysiol. 1993;70:1988–2009. - PubMed
-
- Delgutte B. Physiological models for basic auditory percepts. In: Hawkins HL, McMullen TA, Popper AN, Fay RR, editors. Auditory computation. Springer; New York: 1996. pp. 157–220.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources