

Origin and evolution of the 1918 "Spanish" influenza virus hemagglutinin gene
- PMID: 9990079
- PMCID: PMC15547
- DOI: 10.1073/pnas.96.4.1651
Origin and evolution of the 1918 "Spanish" influenza virus hemagglutinin gene
Abstract
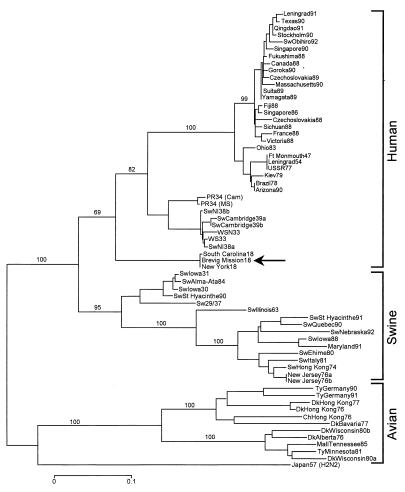
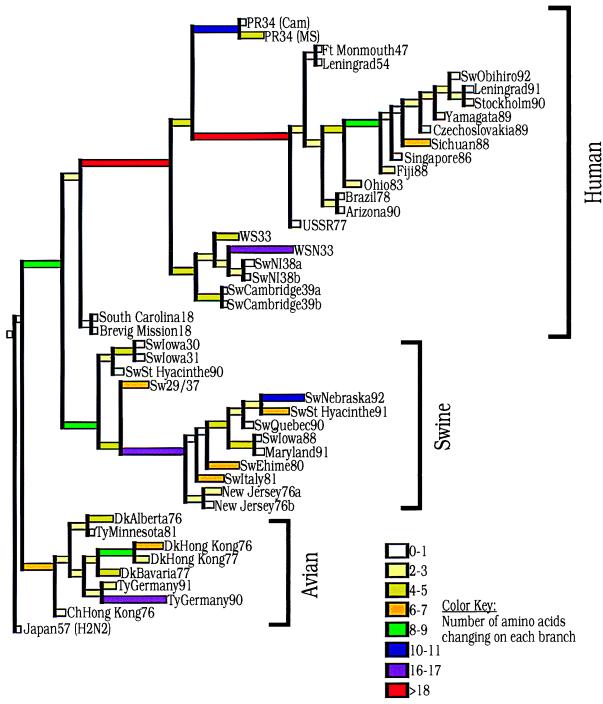
The "Spanish" influenza pandemic killed over 20 million people in 1918 and 1919, making it the worst infectious pandemic in history. Here, we report the complete sequence of the hemagglutinin (HA) gene of the 1918 virus. Influenza RNA for the analysis was isolated from a formalin-fixed, paraffin-embedded lung tissue sample prepared during the autopsy of a victim of the influenza pandemic in 1918. Influenza RNA was also isolated from lung tissue samples from two additional victims of the lethal 1918 influenza: one formalin-fixed, paraffin-embedded sample and one frozen sample obtained by in situ biopsy of the lung of a victim buried in permafrost since 1918. The complete coding sequence of the A/South Carolina/1/18 HA gene was obtained. The HA1 domain sequence was confirmed by using the two additional isolates (A/New York/1/18 and A/Brevig Mission/1/18). The sequences show little variation. Phylogenetic analyses suggest that the 1918 virus HA gene, although more closely related to avian strains than any other mammalian sequence, is mammalian and may have been adapting in humans before 1918.
Figures

Comment in
-
1918 Spanish influenza: the secrets remain elusive.Proc Natl Acad Sci U S A. 1999 Feb 16;96(4):1164-6. doi: 10.1073/pnas.96.4.1164. Proc Natl Acad Sci U S A. 1999. PMID: 9989993 Free PMC article. Review. No abstract available.
References
-
- Crosby A. America’s Forgotten Pandemic. Cambridge, U.K.: Cambridge Univ. Press; 1989.
-
- Taubenberger J K, Reid A H, Krafft A E, Bijwaard K E, Fanning T G. Science. 1997;275:1793–1796. - PubMed
-
- Murphy B, Webster R. In: Fields Virology. Fields B, Knipe D, Howley P, editors. Philadelphia: Lippincott; 1996. pp. 1397–1445.
-
- Kilbourne E. J Am Med Assoc. 1977;237:1225–1228.
-
- Kilbourne, E. D. (1997) J. Infec. Dis.176, Suppl. 1, S29–S31. - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Research Materials
