

High dimensional predictions of suicide risk in 4.2 million US Veterans using ensemble transfer learning
- PMID: 38245528
- PMCID: PMC10799879
- DOI: 10.1038/s41598-024-51762-9
High dimensional predictions of suicide risk in 4.2 million US Veterans using ensemble transfer learning
Abstract
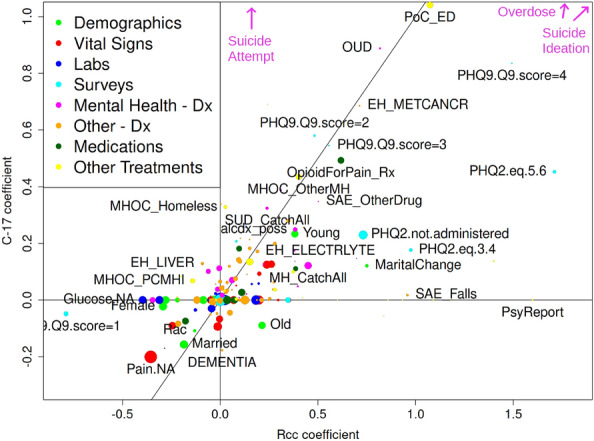
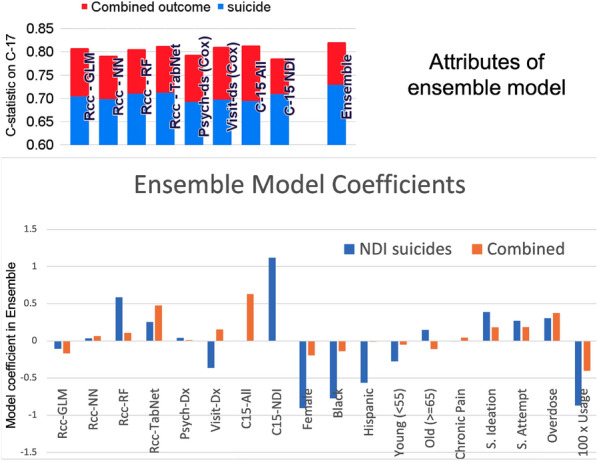
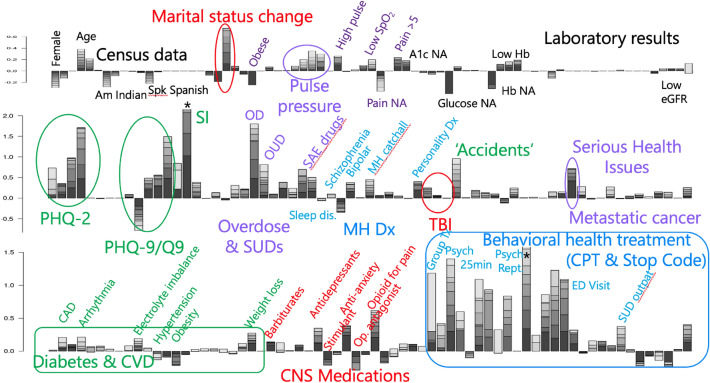
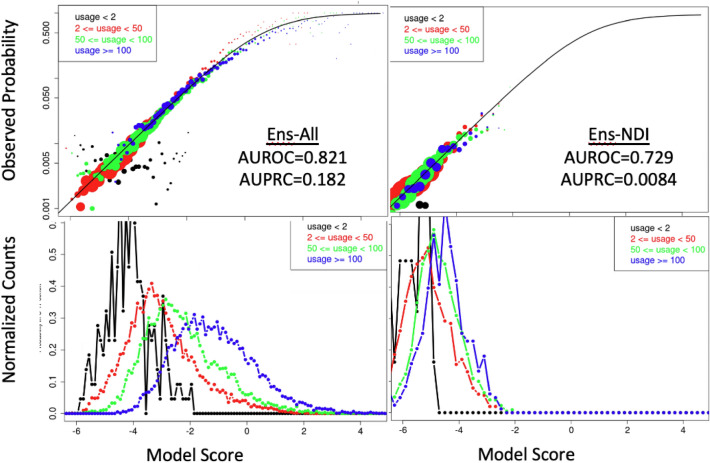
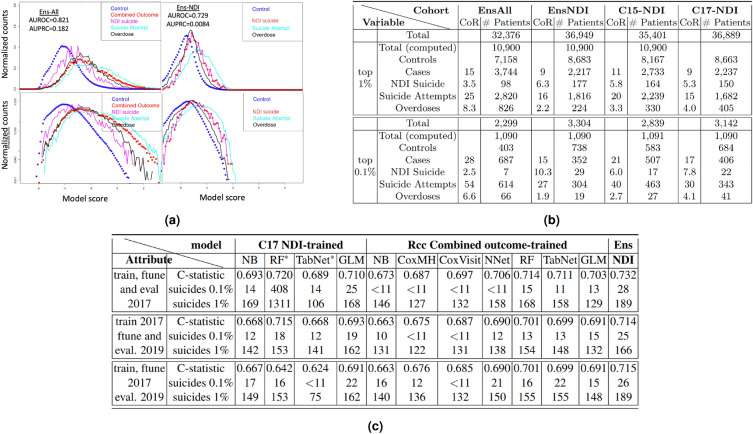
We present an ensemble transfer learning method to predict suicide from Veterans Affairs (VA) electronic medical records (EMR). A diverse set of base models was trained to predict a binary outcome constructed from reported suicide, suicide attempt, and overdose diagnoses with varying choices of study design and prediction methodology. Each model used twenty cross-sectional and 190 longitudinal variables observed in eight time intervals covering 7.5 years prior to the time of prediction. Ensembles of seven base models were created and fine-tuned with ten variables expected to change with study design and outcome definition in order to predict suicide and combined outcome in a prospective cohort. The ensemble models achieved c-statistics of 0.73 on 2-year suicide risk and 0.83 on the combined outcome when predicting on a prospective cohort of [Formula: see text] 4.2 M veterans. The ensembles rely on nonlinear base models trained using a matched retrospective nested case-control (Rcc) study cohort and show good calibration across a diversity of subgroups, including risk strata, age, sex, race, and level of healthcare utilization. In addition, a linear Rcc base model provided a rich set of biological predictors, including indicators of suicide, substance use disorder, mental health diagnoses and treatments, hypoxia and vascular damage, and demographics.
© 2024. This is a U.S. Government work and not under copyright protection in the US; foreign copyright protection may apply.
Conflict of interest statement
The authors declare no competing interests.
Figures



References
-
- Masango SM, Rataemane ST, Motojesi AA. Suicide and suicide risk factors: A literature review. South Afr. Fam. Pract. 2008;50:25–29. doi: 10.1080/20786204.2008.10873774. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
