

Inferring causal molecular networks: empirical assessment through a community-based effort
- PMID: 26901648
- PMCID: PMC4854847
- DOI: 10.1038/nmeth.3773
Inferring causal molecular networks: empirical assessment through a community-based effort
Abstract
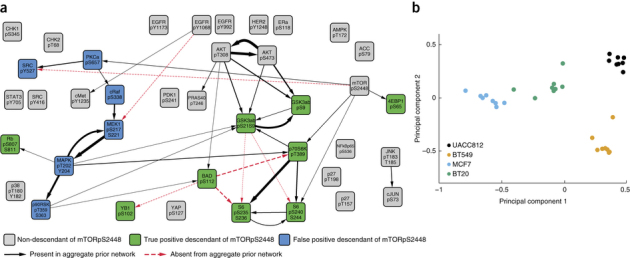
It remains unclear whether causal, rather than merely correlational, relationships in molecular networks can be inferred in complex biological settings. Here we describe the HPN-DREAM network inference challenge, which focused on learning causal influences in signaling networks. We used phosphoprotein data from cancer cell lines as well as in silico data from a nonlinear dynamical model. Using the phosphoprotein data, we scored more than 2,000 networks submitted by challenge participants. The networks spanned 32 biological contexts and were scored in terms of causal validity with respect to unseen interventional data. A number of approaches were effective, and incorporating known biology was generally advantageous. Additional sub-challenges considered time-course prediction and visualization. Our results suggest that learning causal relationships may be feasible in complex settings such as disease states. Furthermore, our scoring approach provides a practical way to empirically assess inferred molecular networks in a causal sense.
Conflict of interest statement
The authors declare no competing financial interests.
Figures
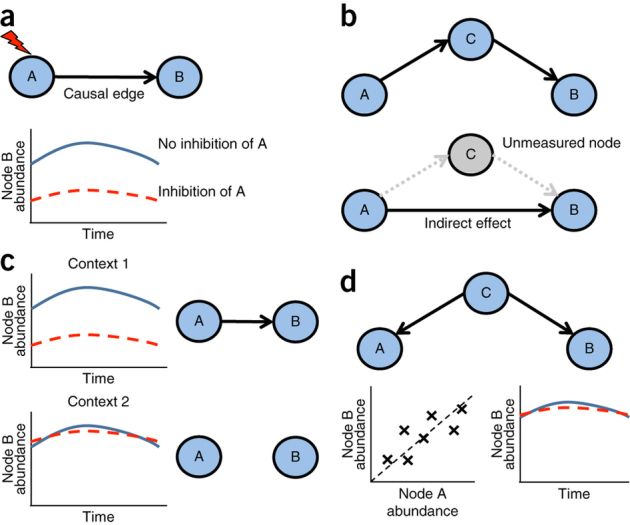
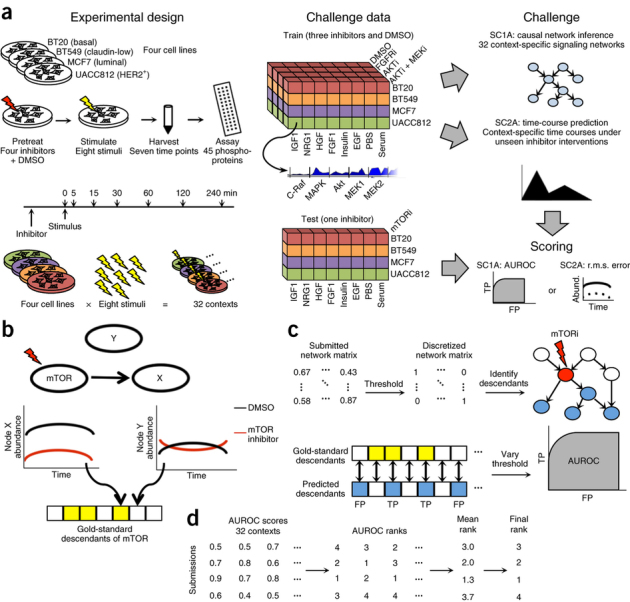
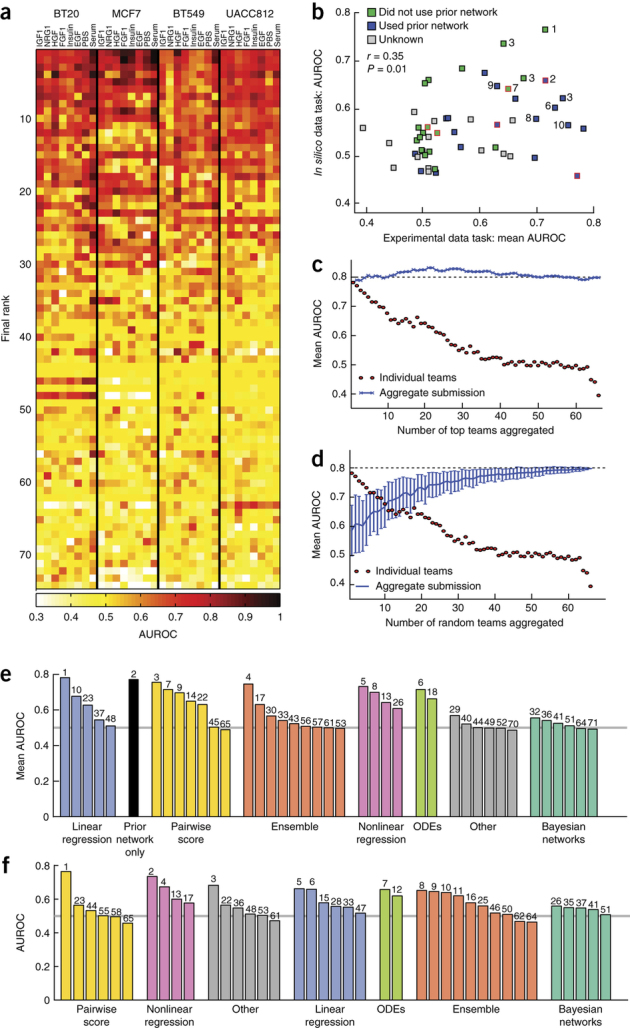
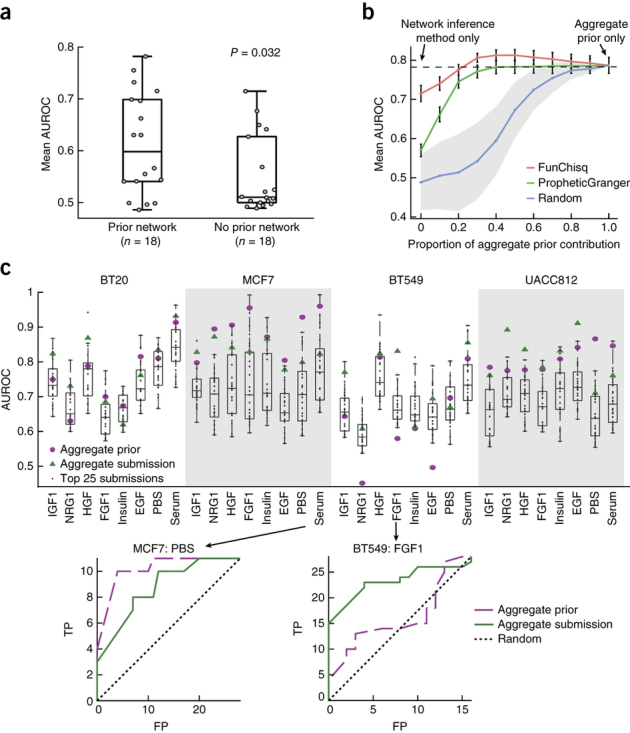
References
Publication types
MeSH terms
Grants and funding
- P30 CA016672/CA/NCI NIH HHS/United States
- R01 GM109031/GM/NIGMS NIH HHS/United States
- MC_UP_1302/1/MRC_/Medical Research Council/United Kingdom
- R00LM010822/LM/NLM NIH HHS/United States
- R01LM011663/LM/NLM NIH HHS/United States
- 1R01GM109031/GM/NIGMS NIH HHS/United States
- U54CA143869/CA/NCI NIH HHS/United States
- U54 CA112970/CA/NCI NIH HHS/United States
- R01 LM011663/LM/NLM NIH HHS/United States
- U54 CA143869/CA/NCI NIH HHS/United States
- 5R01CA180778/CA/NCI NIH HHS/United States
- K25 CA141053/CA/NCI NIH HHS/United States
- R00 LM010822/LM/NLM NIH HHS/United States
- R01 CA180778/CA/NCI NIH HHS/United States
- U54 HG007990/HG/NHGRI NIH HHS/United States
- R01 CA177669/CA/NCI NIH HHS/United States
- R00 LM011673/LM/NLM NIH HHS/United States
- R01 LM012011/LM/NLM NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
