

Insights into the accuracy of social scientists' forecasts of societal change
- PMID: 36759585
- PMCID: PMC10192018
- DOI: 10.1038/s41562-022-01517-1
Insights into the accuracy of social scientists' forecasts of societal change
Abstract
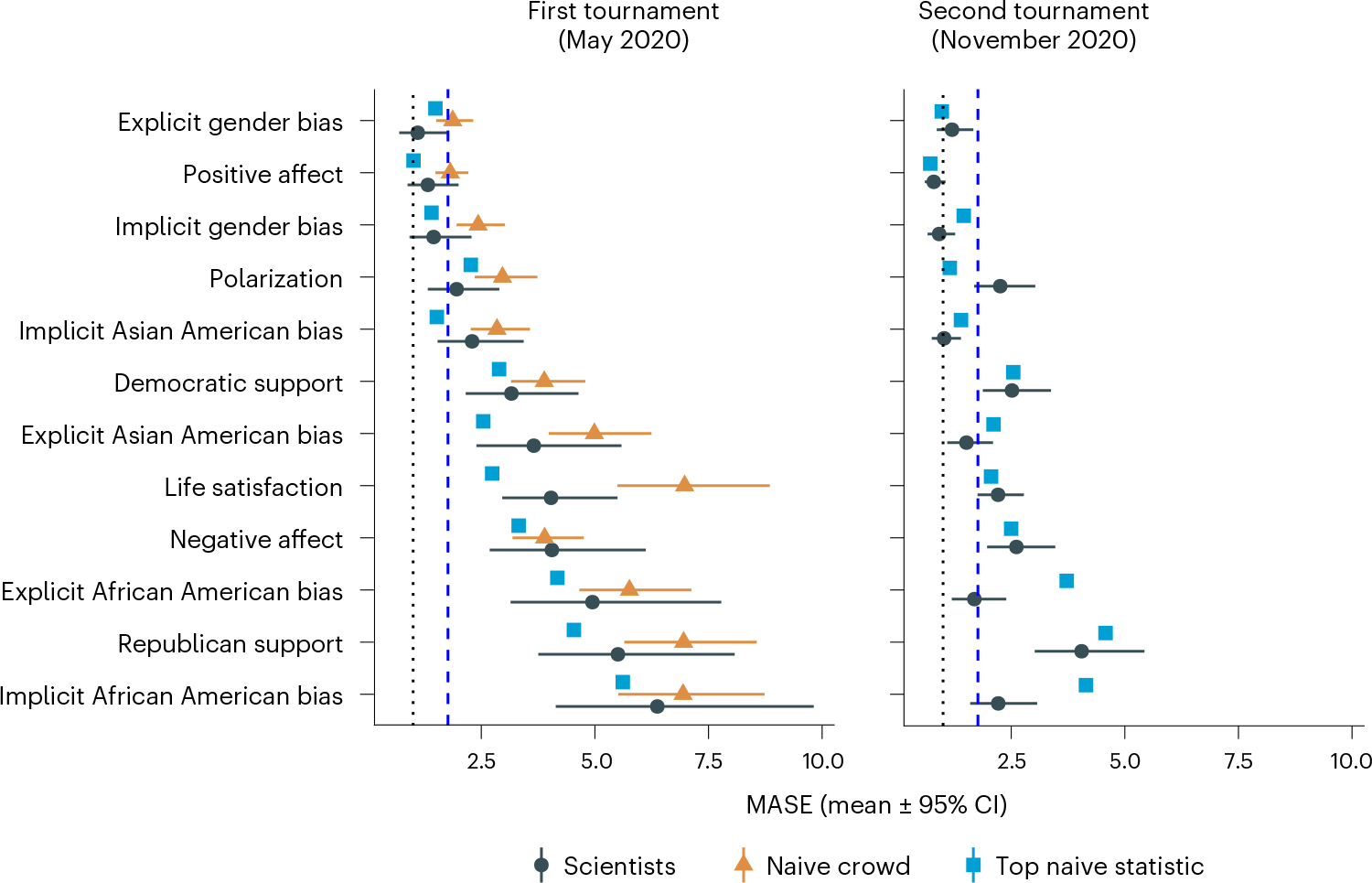
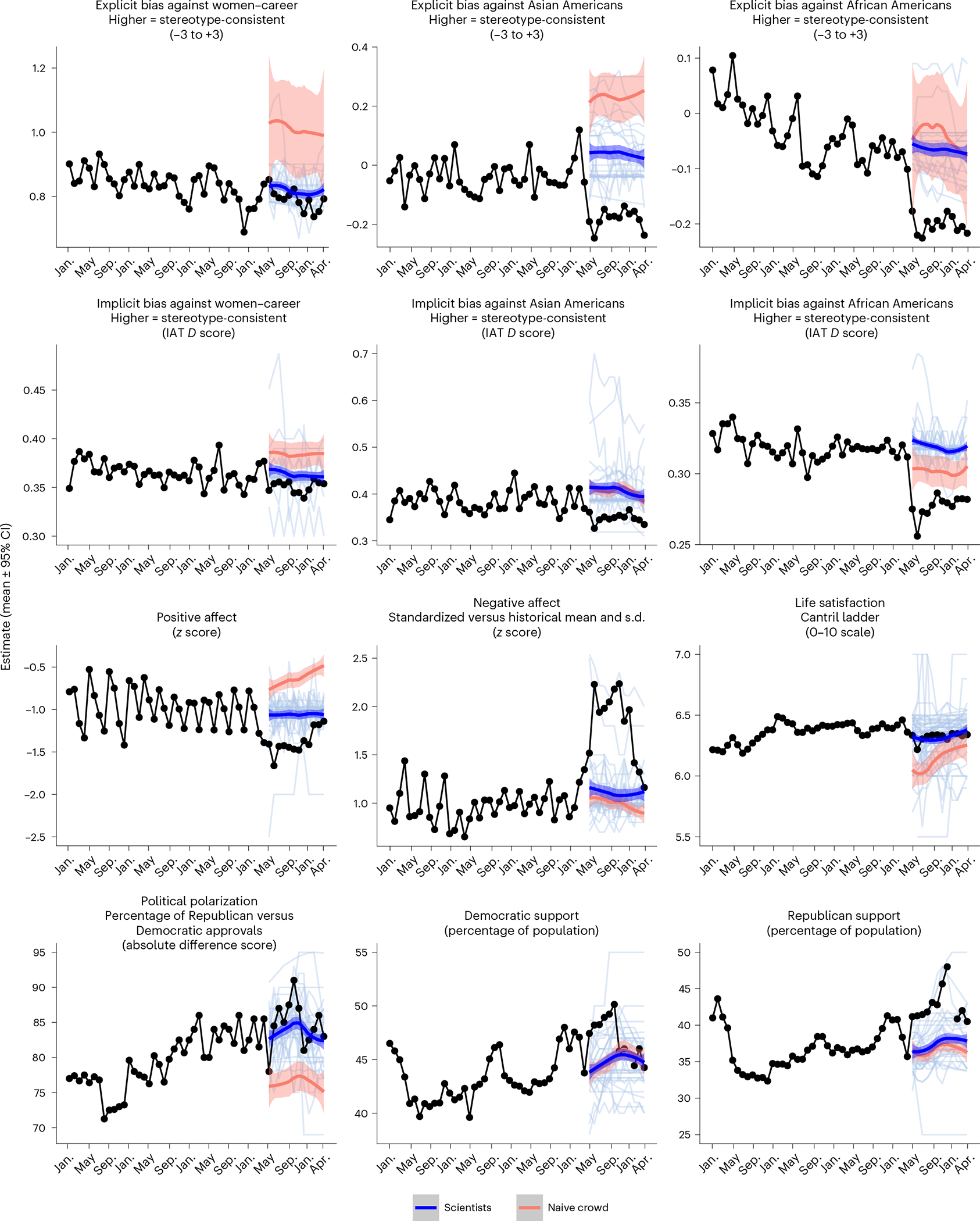
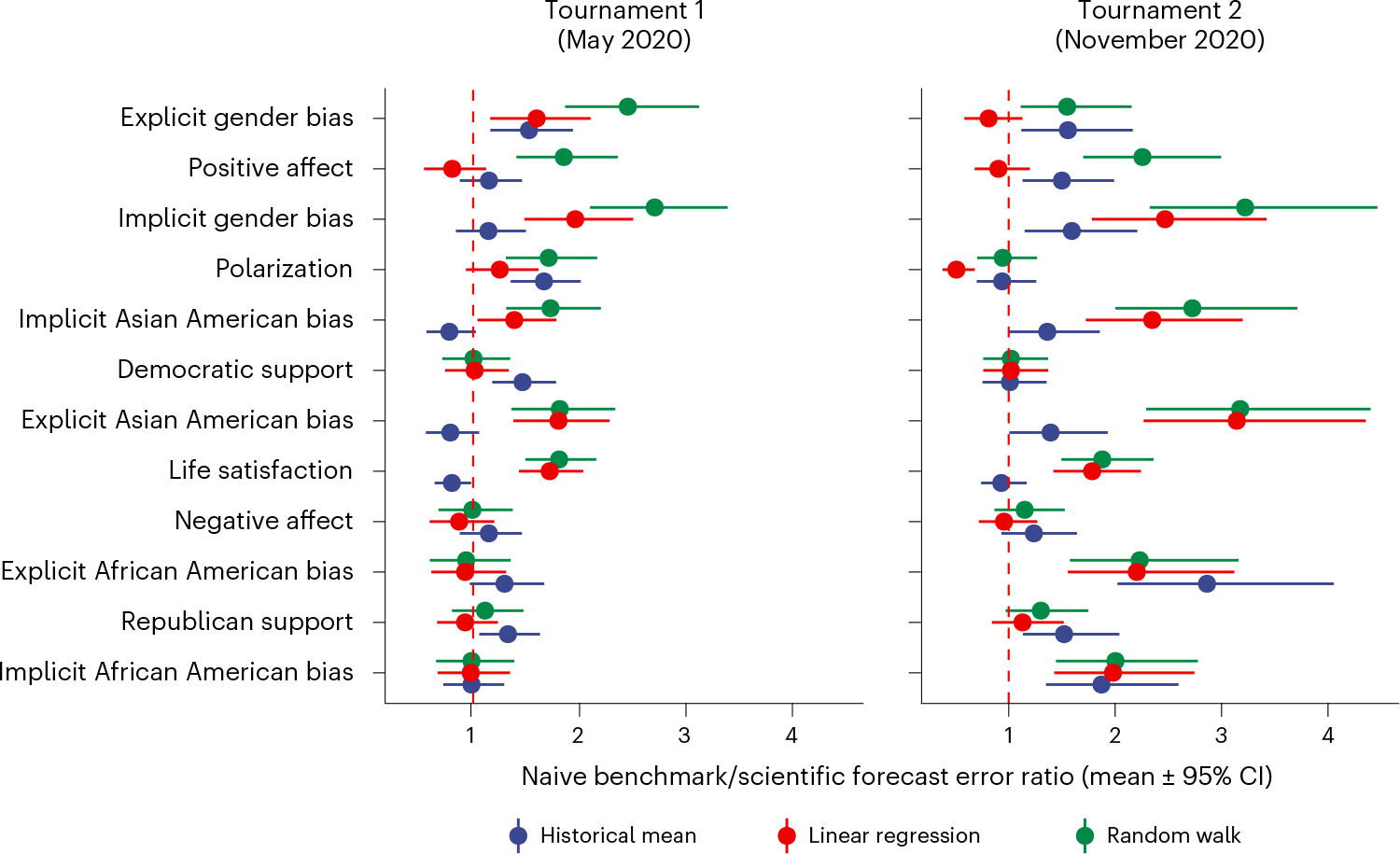
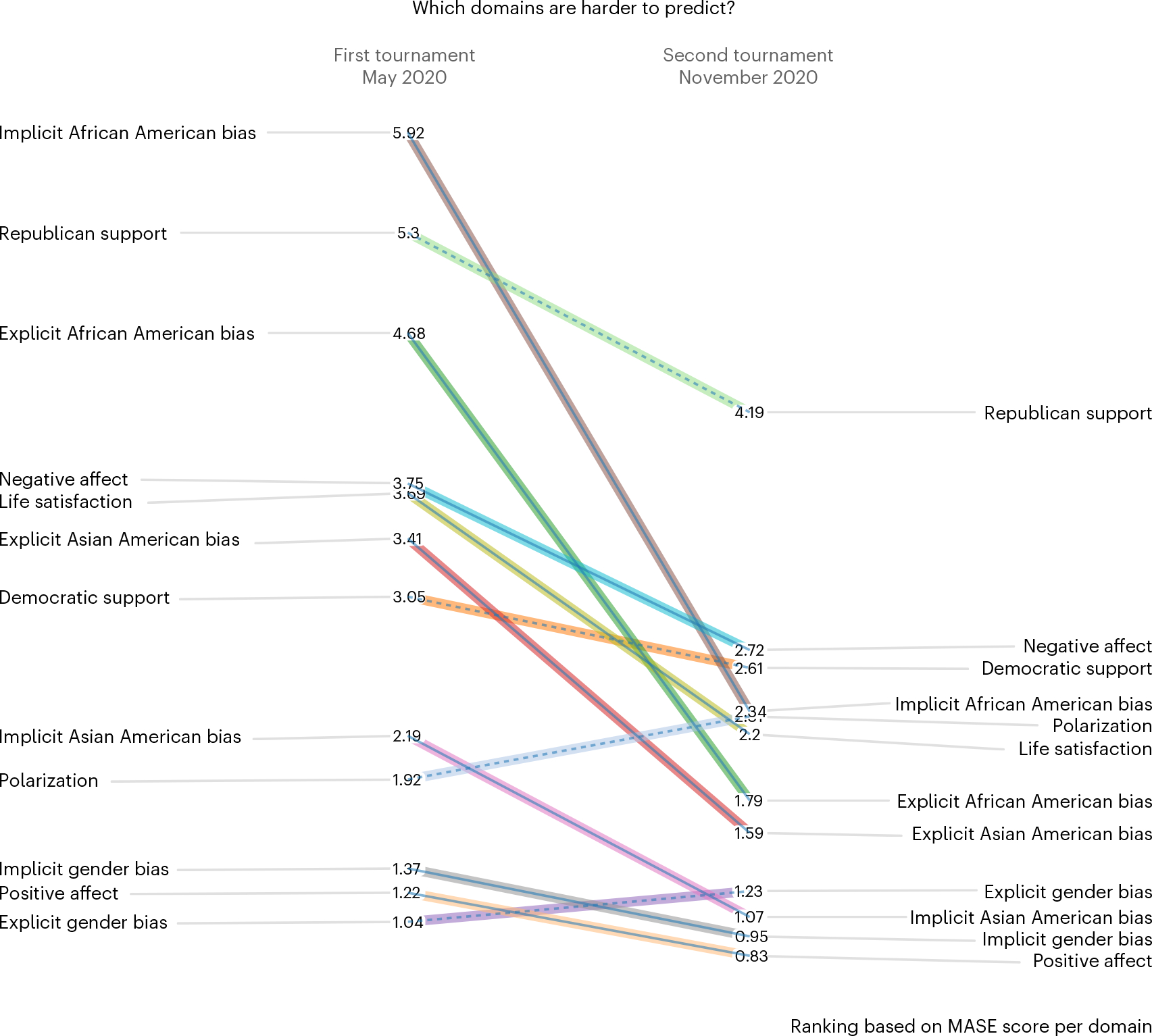
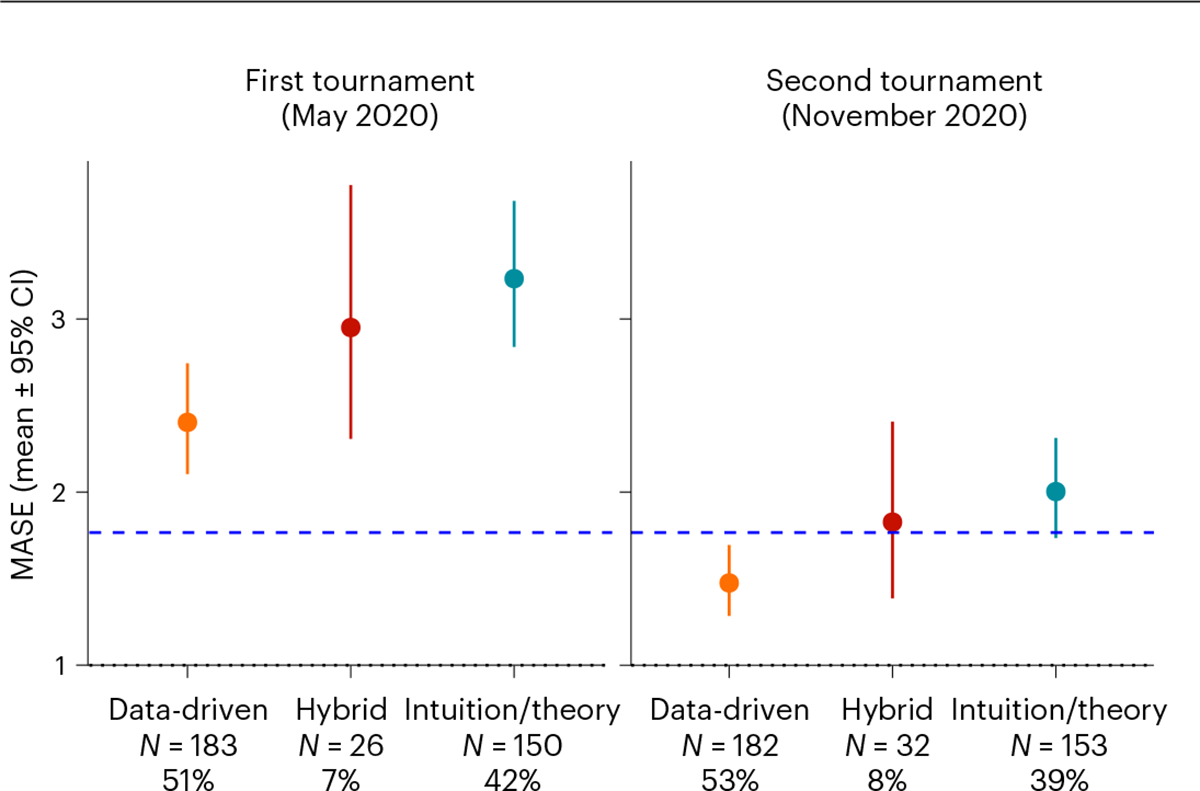
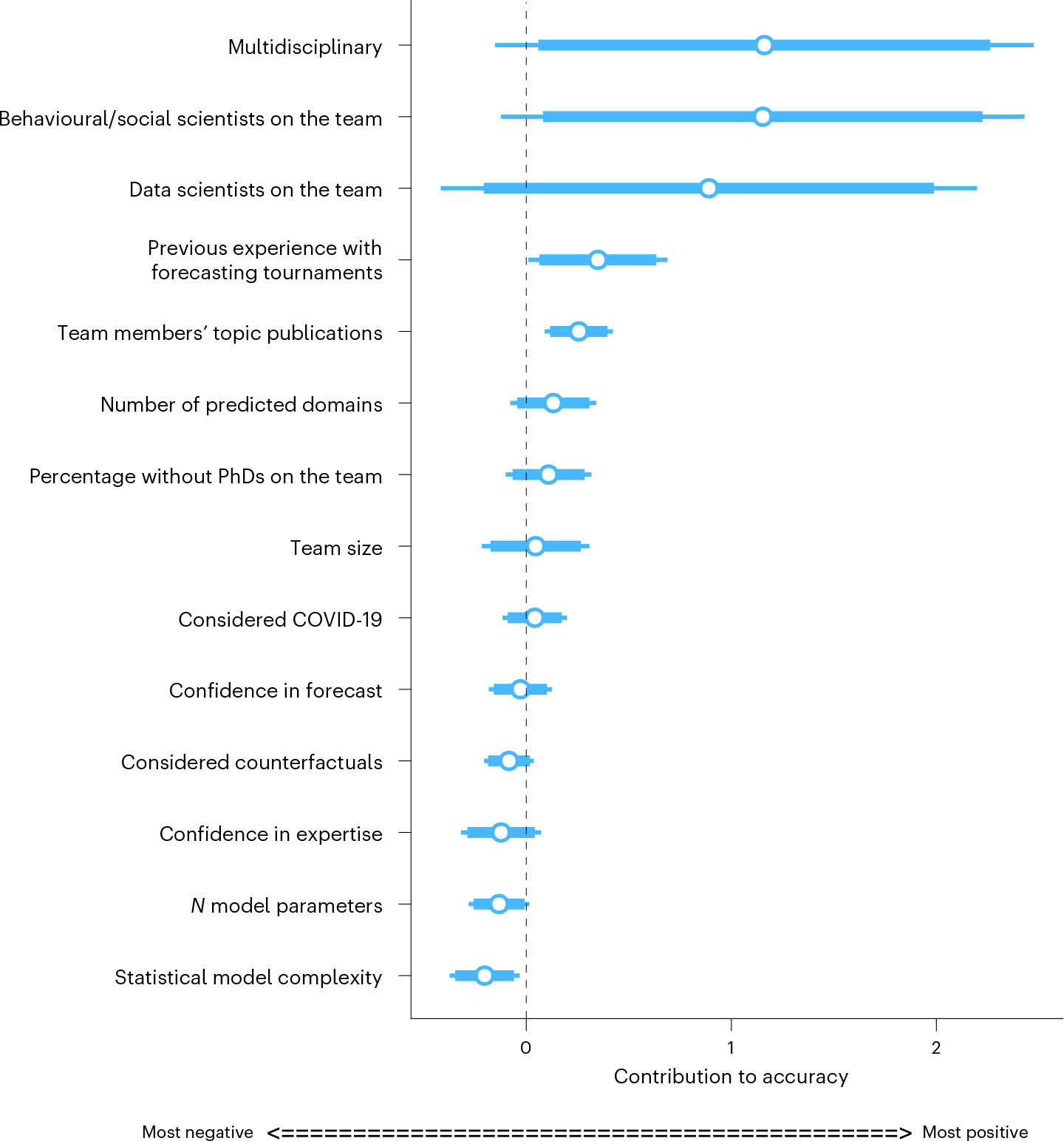
How well can social scientists predict societal change, and what processes underlie their predictions? To answer these questions, we ran two forecasting tournaments testing the accuracy of predictions of societal change in domains commonly studied in the social sciences: ideological preferences, political polarization, life satisfaction, sentiment on social media, and gender-career and racial bias. After we provided them with historical trend data on the relevant domain, social scientists submitted pre-registered monthly forecasts for a year (Tournament 1; N = 86 teams and 359 forecasts), with an opportunity to update forecasts on the basis of new data six months later (Tournament 2; N = 120 teams and 546 forecasts). Benchmarking forecasting accuracy revealed that social scientists' forecasts were on average no more accurate than those of simple statistical models (historical means, random walks or linear regressions) or the aggregate forecasts of a sample from the general public (N = 802). However, scientists were more accurate if they had scientific expertise in a prediction domain, were interdisciplinary, used simpler models and based predictions on prior data.
© 2023. The Author(s), under exclusive licence to Springer Nature Limited.
Conflict of interest statement
Competing interests
The authors declare no competing interests.
Figures
Comment in
-
Predicting the future of society.Nat Hum Behav. 2023 Apr;7(4):478-479. doi: 10.1038/s41562-023-01535-7. Nat Hum Behav. 2023. PMID: 36759587 No abstract available.
References
-
- Hutcherson C et al. On the accuracy, media representation, and public perception of psychological scientists’ judgments of societal change. Preprint at 10.31234/osf.io/g8f9s (2023). - DOI - PubMed
-
- Collins H & Evans R Rethinking Expertise (Univ. of Chicago Press, 2009).
-
- Fama EF Efficient capital markets: a review of theory and empirical work. J. Finance 25, 383–417 (1970).
-
- Tetlock PE Expert Political Judgement: How Good Is It? (Princeton University Press, 2017).
-
- Hofman JM et al. Integrating explanation and prediction in computational social science. Nature 595, 181–188 (2021). - PubMed
