

A generic non-invasive neuromotor interface for human-computer interaction
- PMID: 40702190
- PMCID: PMC12443603
- DOI: 10.1038/s41586-025-09255-w
A generic non-invasive neuromotor interface for human-computer interaction
Abstract
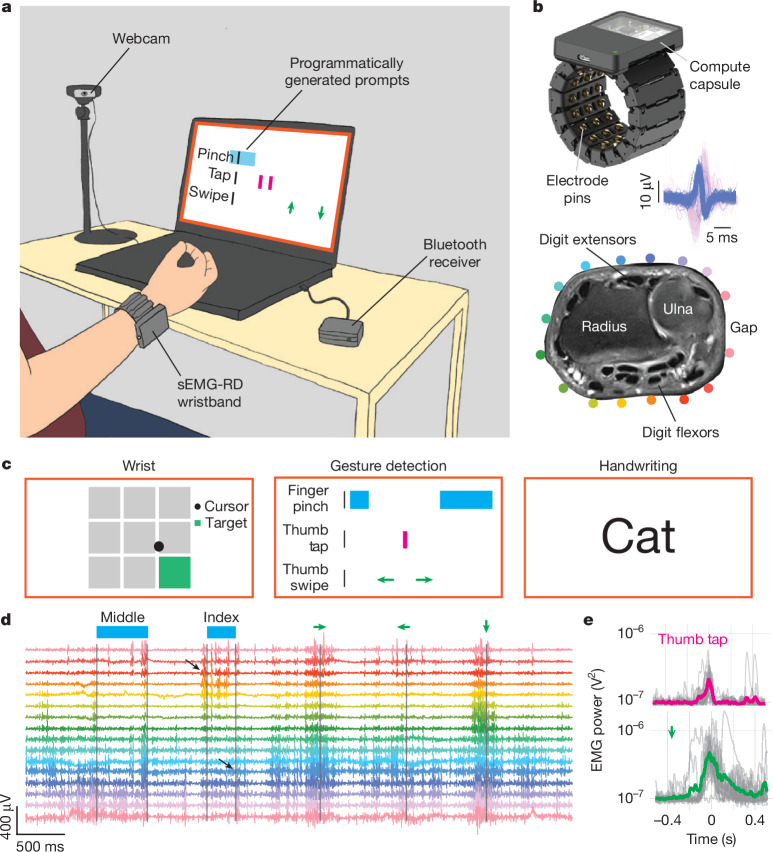
Since the advent of computing, humans have sought computer input technologies that are expressive, intuitive and universal. While diverse modalities have been developed, including keyboards, mice and touchscreens, they require interaction with a device that can be limiting, especially in on-the-go scenarios. Gesture-based systems use cameras or inertial sensors to avoid an intermediary device, but tend to perform well only for unobscured movements. By contrast, brain-computer or neuromotor interfaces that directly interface with the body's electrical signalling have been imagined to solve the interface problem1, but high-bandwidth communication has been demonstrated only using invasive interfaces with bespoke decoders designed for single individuals2-4. Here, we describe the development of a generic non-invasive neuromotor interface that enables computer input decoded from surface electromyography (sEMG). We developed a highly sensitive, easily donned sEMG wristband and a scalable infrastructure for collecting training data from thousands of consenting participants. Together, these data enabled us to develop generic sEMG decoding models that generalize across people. Test users demonstrate a closed-loop median performance of gesture decoding of 0.66 target acquisitions per second in a continuous navigation task, 0.88 gesture detections per second in a discrete-gesture task and handwriting at 20.9 words per minute. We demonstrate that the decoding performance of handwriting models can be further improved by 16% by personalizing sEMG decoding models. To our knowledge, this is the first high-bandwidth neuromotor interface with performant out-of-the-box generalization across people.
© 2025. The Author(s).
Conflict of interest statement
Competing interests: All contributors are current or former employees of Meta Platforms, Inc.
Figures














References
-
- Battye, C. K., Nightingale, A. & Whillis, J. The use of myo-electric currents in the operation of prostheses. J. Bone Joint Surg. Br.37-B, 506–510 (1955). - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
